I'm experimenting a bit with Nim and wondering if there are some general guidelines for speed.
For example, I compile with
c -d:release -d:danger --gc:arc --opt:speed --checks:off --passC:"-O3 -flto -m64" --passL:"-flto" -o:example example.nimDoes this look good?
Any other things to pay attention to? Objects vs ref objects, sequences, tuples? Specific operations that I should prefer over something else?
Thanks in advance!
I think in my book I told you that -d:danger already implies -d:release. Also --opt:speed in unnecessary with d-:danger or with -d:danger. -O3 is the default for danger and release. --checks:off should be included in -d:danger. --passL:"-flto" should be not necessary, yardanico uses that, but from my experience --passC:-flto is sufficieant. No idea what -m64 makes, but you can try --passC:-march=native
Of course you have to care for all the rest also when you want maximum performance.
Thanks a lot!
Also, @araq, I'll try with the devel branch to see if I notice any difference.
Any other suggestions? (I mean unrelated to compiler options)
I don't know if you are using nim.cfg or config.nims or neither, but once you decide on one (or a few) bundles of options then you can package them up for easy reference. E.g., you could add to your $HOME/.config/nim.cfg:
@if r: # Allow short alias -d:r to make fast executables
define:danger
checks:off
panics:on
--passC:"-flto"
@end
Other speed related ideas..Well, most are not Nim-specific but would also apply to C++ or something like that, but efficient data structures, not repeating work, avoiding memory allocation-free cycles by re-using objects when that's not too hard, and so on all can matter. Some of these are sort of Nim-specific. E.g., if you have a seq[T] and can estimate its size ahead of time then pre-allocating that size and using [i] will be faster than growing up by add. Similarly, pre-sizing a Table can save the grow-from zero with many intermediate resizes costs and so on.
It's much easier to give specific guidelines. So, if you can anticipate or profile some small section of code as important to your overall performance and then post that here in the Forum then you can often get good suggestions for how to speed it up.
In c++ i sometimes also got heavy performance improvments when i avoid random memory access. So looping over an array is often times much faster than accessing by key, since the calls can be vectorized better and the cpu cache can work more efficent.
gcc/gpp is also able to log the missed optimization opportunities with -fopt-info-missed and friends.
@enthus1ast's advice is good. To add some numbers, DRAM latency is typically 60..120 ns while a CPU clock cycle is merely 0.2..0.5ns giving 120..600x possible speed ups. Server class CPUs can even do 2..6 dynamic instructions/cycle amplifying the ratio up to 240..3600x. One can not always get such boosts, but it pays to be aware of basic costs.
Those ratios are so large that modern microprocessors take every available opportunity to mask that latency. This in turn makes it all too easy to fool oneself into thinking the ratio is not there by some naive tight, hot loop benchmark. (E.g. doing nothing else allowing the CPU to perfectly predict its near future work and so prefetch memory into L1 caches perfectly.)
But this again is just very general advice/awareness. It's probably multiple whole university level courses to go into all the details while specifics can constrain the scope to something more manageable.
My recommendation is to always profile your code. It's just not possible to guess performance issues beyond a simple program.
VTune is pretty easy to get started with. Just compile with --debuger:native (so that it adds symbols) and open VTune and run your program.
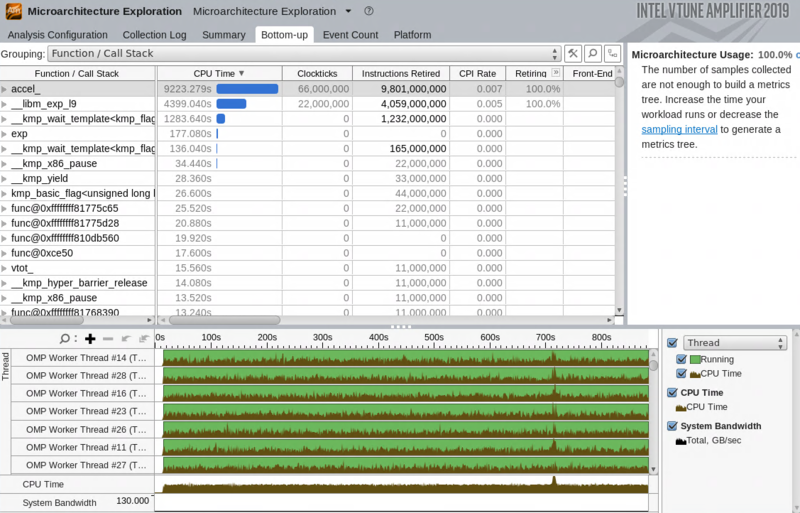
It event allows you to walk through your code looking for hot spots:
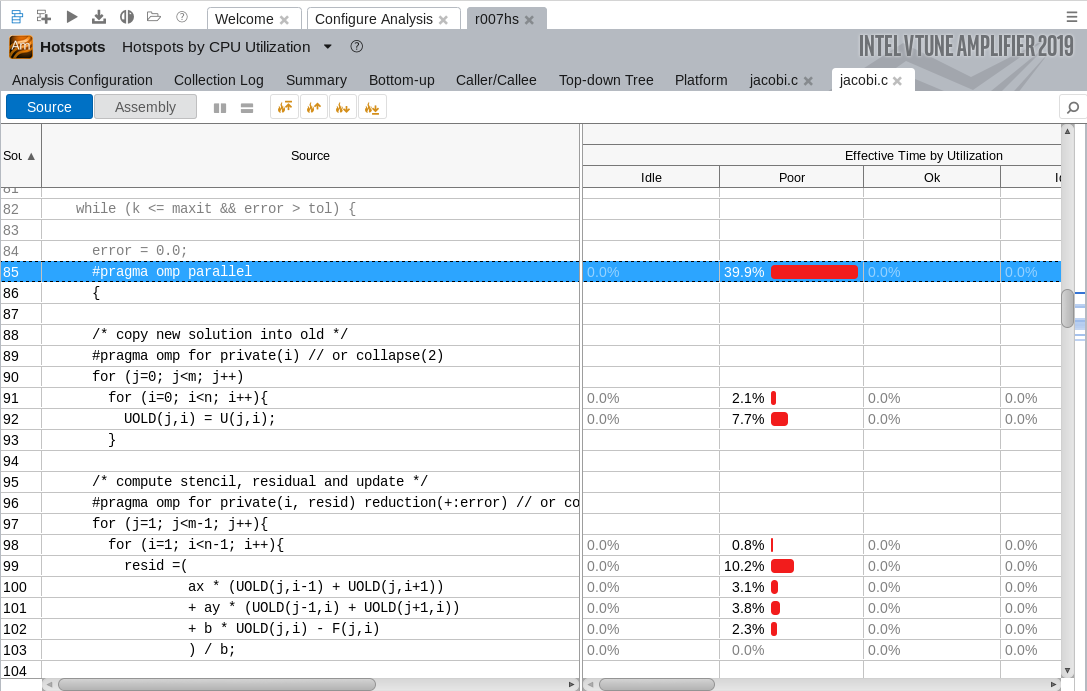
Ohhh... I thought I had to have them so I actived them :P
Now that looks a lot better! Thank you! :D