$ curl -s 'https://forum.nim-lang.org/search.json?q=Bro&q=Bro' \
| jq '.[].creation' \
| while read stamp ; do
date -d @$stamp +"%Y-%m"
done \
| uniq -c
2 2022-04
1 2021-11
1 2021-10
5 2021-09
1 2021-01
1 2020-06
1 2020-02
1 2018-05
1 2017-02
1 2017-01
1 2016-08
1 2016-05
$
bruh
Shouldn't we expect you use "bruv" by now?
@PMunch, I've already mentioned it in the Matrix/IRC, but from my observations, the chat room is considerably more active during the night time in Europe, while you'd expect the opposite if the majority of Nim users was from there. So, possible explanations:
- Our stats are trash.
- Europeans aren't chatty enough.
- Nim is still in the zone of being not accepted enough to be used during working hours, but popular enough to be messing with for the rest of the 24 hours.
Please, don't take this comment seriously.
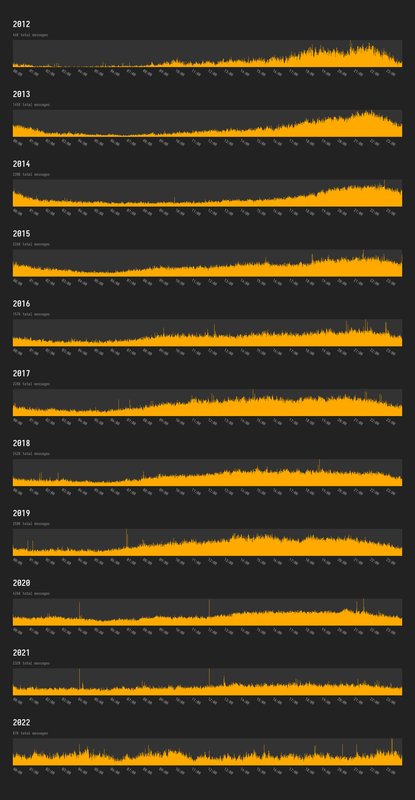
Well, you nerdsniped me... full link here
Looks like there is a bit of a trend. Also interesting to see the massively increased activity in 2020.
(Note this is pretty basic, it includes all entries from the irc logs including user connect/disconnect etc, so numbers are not completely accurate)
Wow, very cool visualisation. How did you create it? Can you share any scripts you've used?
Really interesting to see the late-EU-time majority diminish into flatness. It is interesting that 2020 has so much more activity, my guess is it's due to 1.0 being released but it was released late 2019 (maybe there was a delay?)
@dom96 Thanks! I've uploaded the scripts to github. They're very quick and dirty, please don't judge me for the code - I wrote it over my lunch break!
It's simpler than you might expect, just a small nimja template that generates a gigantic blob of html. I then opened it in firefox and did a screenshot of the whole page (Ctrl+Shift+S which allows you to screenshot the entire page not just the visible area).
If I was actually making a webpage to show it I would do it differently, but my aim was just to make an image I could post here.
I think the increase in 2020 is probably just from people having more time in lockdowns etc. If it was from increased attention due to the 1.0 release I'd expect that to sustain in 2021 but it didn't.
@Yardanico @PMunch yes I did scrape the html pages, sorry about that. I added a delay between each request so hopefully it didn't impact the server. I didn't realise there was a json endpoint, where is it? Good idea making the sqlite database available
I'm assuming the times are UTC, but I'm not actually sure. The times I used are just the ones in the irclogs pages?
My download script just searches for <span> elements containing something that looks like a time (e.g. "15:31:17") and saves them each on a line in a file for that date (so I don't have to actually keep all the logs, I wasn't sure how big they'd be overall)
To be fair, scraping the html is more resilient: the early logs were only saved as HTML (so you will get 404s when requesting the JSON).
Wasn't expecting this graph to just be HTML, really nice styling!
To be fair, scraping the html is more resilient: the early logs were only saved as HTML (so you will get 404s when requesting the JSON).
That's good to know. So the server will serve old html or process new json into html on request? Where's the code for the irclogs backend?
Wasn't expecting this graph to just be HTML, really nice styling!
Thanks :)
So the server will serve old html or process new json into html on request? Where's the code for the irclogs backend?