Hi! I decided to google it, and i found few sites, just want to share with you
side by side comparison of several programming languages
maybe someone can write it better (w/o GC i don't know actually =)
just small thing to get more attention, you know ;)
The blog post is 7 years old obviously which could mean different things for both Nim and Rust, but Nim has changed a lot more since, notice there is a nil seq in there. So the results today might be different but not sure how much. For all I know LLVM could have been vectorizing conway's game of life for Rust.
The benchmark game clone on the other hand is weird. Compare this benchmark between Nim and Rust. Nim is reimplemented from some language like JS and Rust is hand written, seemingly because the creator of the repo is familiar with Rust and not with Nim.
OrderedTableRef instead of OrderedTable + var, method instead of proc, lcg being a double-closure are some obvious things, but there is the real bottleneck that Rust can do let Some(&v) = table.get(k) while Nim does if k in table: let v = table.get(k). There is already withValue for this in tables but it only seems to be overloaded for Table. There is even lru.tbl[key] = v and then immediately after lru.tbl[key] = value in put which I'm pretty sure is meaningless even for OrderedTable.
A lot of this boils down to different languages providing different APIs. Otherwise system languages usually perform about the same, only when things like GC or dynamic typing get in the way do things change, which is the minimal case at this point for Nim (that benchmark does not need the GC).
OrderedTableRef instead of OrderedTable + var, method instead of proc, lcg being a double-closure are some obvious things, but there is the real bottleneck that Rust can do let Some(&v) = table.get(k) while Nim does if k in table: let v = table.get(k). There is already withValue for this in tables but it only seems to be overloaded for Table.
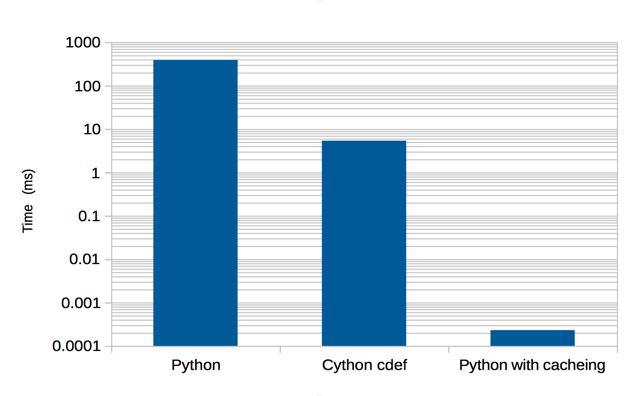
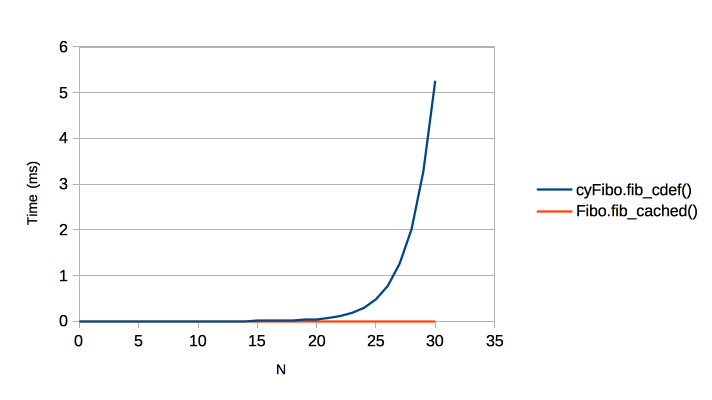
A few weeks back I toyed with the LRU example from the "Programming Language Benchmark". After some toying around I got it beating the Rust version by ~15%. It's largely driven by different APIs and data structures (or parallelism).
First, optimizing the low hanging fruit like swapping method's (?) for proc's and a iterator for the Rust single integer version, etc. It didn't the performance too much (though some). Not nearly as much as I'd expected.
Toying with optimizer flags helped a bunch! Compiling with LTO really helped: nim c -d:release --gc:arc --clang.options.speed="-O4 -flto" --clang.options.linker="-flto" lru2.nim. It'd actually seem like it might make sense to add flags for useFlto or something in the Nim compiler.
Though that still left it at about 0.38s (Rust) vs 0.52s (Nim), which is way better than the original but I wasn't satisfied. So I pecked around Nimble and found LRUCache. The main difference is that it uses DoublyLinkedList's that require "unsafe" in Rust (IIRC).
Using LRUCache and LTO results in 0.32s (Nim) vs 0.38s (Rust) on my M1 MacBook Air. It holds for larger input values as well, so load timing isn't much of an issue. Counting the proc's used from LRUCache with lru.nim gives a 129 lines vs the Rust version's 133 lines.
Here's the updated LRU version:
import os, strutils, tables, options
import lrucache
const A:uint32 = 1103515245
const C:uint32 = 12345
const M:uint32 = 1 shl 31
type LCG = uint32
proc newLCG(seed: uint32): LCG =
result = seed.LCG
proc next(val: var LCG): uint32 {.inline.} =
val = (A*val+C) mod M
result = val.uint32
let n = if paramCount() > 0: parseInt(paramStr(1)) else: 100
let lru = newLRUCache[LCG, LCG](10)
var rng0 = newLCG(0)
var rng1 = newLCG(1)
var hit = 0
var missed = 0
for i in 0..<n:
let n0 = rng0.next() mod 100
lru[n0] = n0
let n1 = rng1.next() mod 100
if n1 in lru:
discard lru[n1]
inc hit
else:
inc missed
echo hit
echo missed
Nice work @elcritch. Not sure of the VC history of when it arose, but you probably would like to know that stock nim.cfg has had -d:lto for a while. It does not always help, but often can.
Also, this ancient and bad/extremely biased benchmark was discussed a little recently. Unfortunately, there has almost always been a culture of misleading benchmarks (in everything). Whole books can be (and almost surely have been) written on the topic. This issue is especially bad in "which prog.lang is faster?" conversations because these particular convos attract people who are "new" to at least one new language in a bundle they assess. Besides that, they're often inexperienced/"new to being new". As with any kind of "news cycle", over-concluding (being more exciting) gets more propagation even if origin studies have all the right qualified language/setup to be well done & reproducible (unlikely). About all that can be done is, like @elcritch, work through details again & again, explaining mistakes and hope others do, too.
system languages usually perform about the same
for sure!
here is more modern (only 2 years old)) benchmark , that shows almost zero difference in speed from ++
Rust
wanted to make some tests in Bevy, but got GPU issue or something - too much safety? hahaha
there is ARC now which is about the same as Rust's memory management. These will usually be the same speed as manually memory managed code.
would be nice to see this sentence on main page ;)
explaining mistakes and hope others do, too
we've got already some traction =)
Faster implementation of fasta benchmark in Nim (#244) 1 hour ago
thank you @can-lehmann !
i think this topic is extremely important, because any discussion starts from performance
another important topic, which is i think needs to be lit up - is the ecosystem, and i've already found out that BINDINGS is a zero penalty thing and we already have a bunch of bindings for some major lib's
all of that should be a well maintained part of lang promo.