Hi everyone,
I’ve been working on a small experimental operating system kernel called Rk-C, written mainly in Nim, targeting RISC-V 64-bit on QEMU + OpenSBI.
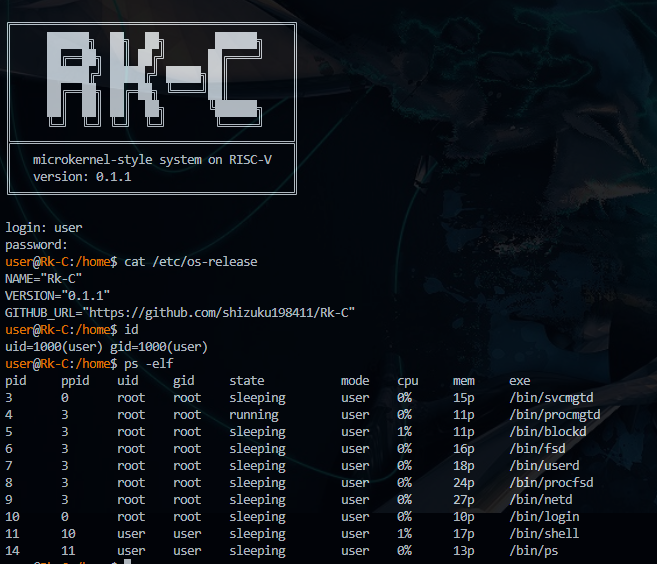
Repository: https://github.com/shizuku198411/Rk-C
The project started as a rewrite of my previous C-based kernel. At this point it has grown into a small microkernel-style OS with user-space services, a shell, a custom executable format, basic filesystem support, process management, networking experiments, and some security-oriented mechanisms.
Some of the current features include:
- RISC-V 64-bit kernel running in S-mode.
- User-mode applications.
- Preemptive scheduling using timer interrupts.
- User-space services.
- A custom executable format called RKX.
- Capability metadata in RKX, with kernel-side capability validation.
- IPC-based service communication.
- Basic user/root support, login flow, and file permissions.
- Experimental networking, including ARP, IPv4, ICMP, UDP, DNS, TCP, HTTP, and early TLS work.
Why Nim?
One of the most interesting parts of this project has been using Nim for kernel development.
I originally wrote the kernel in C, but Nim has been a very comfortable middle ground for this kind of work. It still allows low-level control such as pointer operations, MMIO access, custom ABI boundaries, packed structs, and freestanding builds. At the same time, it provides a much more modern programming experience than C.
Compared with C, Nim makes it easier to structure the code into modules, define clear types, and write readable user-space tools and services. Compared with Rust, Nim feels lighter for this kind of small experimental kernel: less ceremony, easier freestanding experimentation, and more direct control when I need it.
Another practical reason is AI-assisted coding. Nim’s syntax is compact and readable, and the language is expressive without being too verbose. That makes it easier to iterate with AI tools: reviewing code, refactoring modules, generating repetitive boilerplate, and exploring implementation ideas all feel smoother than they did in my C version.
In short, Nim lets me write low-level kernel code and higher-level user-space services in the same language, without the project feeling split between “kernel C” and “application language”.
Why build a kernel now?
The motivation is partly educational, but also architectural.
Modern general-purpose kernels have to support a huge range of hardware, filesystems, network protocols, compatibility layers, drivers, and optional features. That flexibility is extremely valuable, but it also increases complexity and attack surface.
My goal with Rk-C is not to replace Linux or claim that this design is better. Linux solves a much larger and harder problem. Instead, I wanted to explore a smaller kernel that only implements the features I personally want to use and understand.
The idea is:
- keep the kernel small,
- move privileged functionality into user-space services,
- make executable metadata explicit through RKX,
- use capabilities to limit privileged operations,
- and avoid carrying features that are unnecessary for my own use case.
For example, Rk-C’s RKX executable format includes metadata such as requested capabilities and stack size. However, the kernel does not trust this metadata directly. It grants capabilities only according to a trusted policy for immutable core applications under /bin, and IPC packets are stamped by the kernel with the sender’s effective capabilities. This helps user-space services avoid confused-deputy style mistakes.
This is still an experimental hobby OS, but the project has reached a point where the core pieces are starting to fit together. Nim has been a surprisingly good fit for building both the kernel and the surrounding userland.
- A linker script defines the physical layout of the kernel image.
- A small RISC-V assembly entry point sets up the CPU state and stack.
- Nim takes over almost immediately and performs the rest of the kernel initialization.
This makes the low-level boundary explicit, while still allowing most of the kernel initialization logic to be written in structured Nim code.
1. Linker script: defining the kernel layout
The kernel is linked at 0x80200000, which is where OpenSBI jumps to the payload on QEMU virt.
ENTRY(boot)
KERNEL_BASE = 0x80200000;
KERNEL_STACK_SIZE = 64K;
FREE_RAM_SIZE = 128M;
SECTIONS
{
. = KERNEL_BASE;
__kernel_base = .;
.text : ALIGN(16) {
__text_start = .;
KEEP(*(.text.boot))
KEEP(*(.text.trap_entry))
*(.text .text.*)
__text_end = .;
}
. = ALIGN(4096);
.rodata : ALIGN(4096) {
__rodata_start = .;
*(.srodata .srodata.*)
*(.rodata .rodata.*)
*(.rdata .rdata.*)
__rodata_end = .;
}
. = ALIGN(4096);
.data : ALIGN(4096) {
__data_start = .;
PROVIDE(__global_pointer$ = . + 0x800);
*(.sdata .sdata.*)
*(.data .data.*)
__data_end = .;
}
. = ALIGN(4096);
.bss (NOLOAD) : ALIGN(4096) {
__bss_start = .;
*(.sbss .sbss.*)
*(.bss .bss.*)
*(COMMON)
__bss_end = .;
}
. = ALIGN(4096);
__kernel_end = .;
.kernel_stack (NOLOAD) : ALIGN(4096) {
__stack_bottom = .;
. += KERNEL_STACK_SIZE;
__stack_top = .;
}
. = ALIGN(4096);
.free_ram (NOLOAD) : ALIGN(4096) {
__free_ram_start = .;
. += FREE_RAM_SIZE;
__free_ram_end = .;
}
}The linker script exports symbols such as __bss_start, __stack_top, and __free_ram_start. These symbols are later imported directly from Nim.
2. Assembly: minimal CPU setup
The assembly boot code is intentionally small. It parks secondary harts, initializes gp, sets the boot stack, and jumps into Nim.
.section .text.boot
.global boot
boot:
# OpenSBI passes:
# a0 = hartid
# a1 = fdt address
#
# currently Rk-C supports only hart0.
# park secondary harts before touching the shared boot stack.
bnez a0, park_hart
.option push
.option norelax
lla gp, __global_pointer$
.option pop
lla t0, __stack_top
mv sp, t0
csrw sscratch, sp
j kernel_main
park_hart:
# disable supervisor interrupts for secondary harts.
csrw sie, zero
csrw sip, zero
park_loop:
wfi
j park_loopThis is still very close to what I would write in C-based kernel development. The difference is that after this point, the kernel can move into Nim almost immediately.
3. Nim: the kernel entry point
The exported Nim function becomes the real kernel entry point.
proc parkHart() {.noreturn.} =
while true:
asm "wfi"
proc kernel_main*(hartid: U64, dtb: pointer) {.exportc, cdecl.} =
if hartid != U64(0):
parkHart()
kernelBootstrap(hartid, dtb)
schedule()
panic("scheduler returned to kernel_main")This function still uses low-level concepts directly:
- explicit ABI export with {.exportc, cdecl.},
- raw pointer argument for the device tree blob,
- inline assembly for wfi,
- fixed-width integer types such as U64.
But the code itself remains compact and readable.
4. Importing linker symbols from Nim
One thing I really like is that Nim can directly import linker symbols and use them as addresses.
var
bssStartSym {.importc: "__bss_start".}: char
bssEndSym {.importc: "__bss_end".}: char
kernelBaseSym {.importc: "__kernel_base".}: char
kernelEndSym {.importc: "__kernel_end".}: char
stackBottomSym {.importc: "__stack_bottom".}: char
stackTopSym {.importc: "__stack_top".}: char
freeRamStartSym {.importc: "__free_ram_start".}: char
freeRamEndSym {.importc: "__free_ram_end".}: charFor example, clearing .bss is written in Nim, but still works directly with linker-provided addresses:
proc clearBss() =
let start = cast[U64](addr bssStartSym)
let last = cast[U64](addr bssEndSym)
let size = last - start
zeroMem(cast[pointer](start), size)
if not isZeroed(cast[pointer](start), size):
panic("failed to bss zero clear")This is a good example of why Nim feels comfortable for kernel development: it does not hide the low-level details, but it lets me express them in a cleaner way.
5. Kernel initialization in Nim
After the very small assembly entry point, most initialization is written in Nim:
proc kernelBootstrap*(hartid: U64, dtb: pointer) =
putChar('\n')
printBootMsg("initial setup:\n")
printBootMsg(" clear bss ")
clearBss()
println("OK")
printBootMsg(" set trap vector ")
setTrapVector()
println("OK")
printBootMsg(" initialize memory allocator ")
let memInfo = memoryInit()
println("OK")
printBootMsg(" initialize process ")
processInit()
println("OK")
printBootMsg(" enable Sv39 ")
enableSv39(memInfo)
println("OK")
printBootMsg("initialize file system:\n")
fsInit()
printBootMsg(" enable timer interrupt ")
setNextTimer()
enableTimerInterrupt()
println("OK")
addressInfo(hartid, dtb, memInfo)
print("\n")
if createKernelProcessNamed(bootTask, "boot_task") < 0:
panic("failed to create boot task")This is the part where Nim feels especially useful. The initialization sequence is readable, modular, and easy to refactor, but it still controls low-level features such as:
- trap vector setup,
- physical memory initialization,
- Sv39 paging,
- timer interrupts,
- process initialization,
- kernel task creation.
6. Enabling Sv39 paging
Even paging setup can stay relatively readable:
proc enableSv39(memInfo: MemoryInfo) =
kernelRootPageTable = createKernelMappedPageTable()
if kernelRootPageTable == nil:
panic("failed to allocate kernel root page table")
setKernelPageTable(kernelRootPageTable)
let satp = makeSatp(cast[PAddr](kernelRootPageTable))
paging.flushTlb()
arch.writeSatp(satp)
paging.flushTlb()
discard memInfoThis code is still doing real kernel work: creating a page table, writing satp, and flushing the TLB. But it is much easier to read than an equivalent large C initialization function.
Why this matters
For me, this boot path shows why Nim is a good fit for this project.
Assembly is still used where it makes sense: the very first CPU setup and trap/context boundaries. The linker script still controls the exact memory layout. But once the minimal machine state is ready, Nim can take over and express the rest of the kernel in a structured way.
Compared with C, Nim gives me:
- modules and clearer code organization,
- stronger type definitions,
- readable object-based structures,
- templates and compile-time features when needed,
- less boilerplate in userland tools and services.
Compared with Rust, Nim feels lightweight for this kind of experimental kernel. It lets me directly use pointers, casts, packed structures, inline assembly, custom calling conventions, and freestanding builds without too much ceremony.
This balance is the main reason I started rewriting my C kernel in Nim. It still feels close to the hardware, but it also scales better when the project grows into user-space services, shell commands, networking tools, and filesystem utilities.
Thanks! Yes, that is an interesting direction. At the moment Rk-C is built with --mm:none and avoids Nim's heap-managed features in both the kernel and userland. I currently use fixed-size buffers and explicit memory handling.
Getting an osalloc-like layer working would be a good next step, especially for user-space applications. My current plan is probably to keep the kernel side conservative for now, but experiment with a userland allocator/runtime so that ARC/ORC-managed Nim code can be used more naturally in applications :)
Thanks for the suggestion!
I tried this direction and now have an experimental userland ORC setup working in Rk-C.
Since Rk-C is a microkernel-style OS, I’m starting from userland services rather than the kernel itself. The kernel still uses explicit page-based memory management, but user processes now have a brk / sbrk backed heap. I added a small malloc / free bridge on top of that, so selected userland programs can use Nim’s ORC runtime.
One example is procfsd, which is Rk-C’s own procfs-like virtual filesystem service. It runs in userland and generates files such as process, service, memory, and fd information.
For example:
var
renderedText: string = ""
procInfos: seq[SysProcessInfo] = @[]
services: seq[SysServiceInfo] = @[]
proc appendChar(pos: var U32, ch: char) =
if pos + U32(1) < ProcFsBufSize:
renderedText.add(ch)
inc posThis has made the userland service code much easier to write and maintain. The main benefit is that Rk-C can keep the kernel small and explicit, while higher-level userland services can gradually use more of Nim’s memory management features.
I see this as a first step toward building a stronger ORC foundation for both userland and, eventually, selected kernel-side components. I’ll keep the kernel conservative for now, but this gives me a practical path to expand Nim-managed allocation in a controlled way ;)
Thank you!
I’m glad the comparison made sense. I mentioned C and Rust mainly because they are the most common reference points for low-level/kernel development today, especially with Rust getting more attention recently.
My intention is not to say that Nim is a replacement for either of them. For this project, Nim feels like an interesting middle ground: close enough to C for low-level control, but still expressive enough to make userland services and tooling pleasant to write.
That balance has been one of the most enjoyable parts of building Rk-C so far.