Nev version 0.3 released
Hi, it's been a while and it's time for another release.
A lot has happened since last time, and I'll try to give a more detailed overview here.
You can download pre built binaries for some platforms here.
New name
Now the most obvious change is the name, I wanted something shorter and easier to pronounce :^)
Text representation
In the last version text was represented internally as an array of lines, which worked somewhat well for a while but I was never happy with the bad performance for large files and long lines, both for rendering and editing.
I considered gap buffers (which I implemented a few years ago in another text editor), ropes and piece tables, but ended up going with ropes when I learned about Zeds design based on sum trees. Ultimately the deciding factors where:
- Sum trees (and therefore ropes) can be safely shared across threads thanks to being immutable and using atomic reference counting)
- Fast modification is done by sharing data with old trees when "modifying" (really creating a new tree)
- Sum trees can be used for a bunch of other things (see text rendering below)
At some point I also decided to try to implement a CRDT (again based on Zeds design), so in the future Nev will also have collaboration features, but right now only the groundwork is done.
After switching to ropes I was also able to move a bunch of things to background threads which previously had to run on the main thread, because I could now easily share the file content with other threads.
Treesitter parsing is one of the things now done on a background thread. Usually you don't need that, as treesitter is fast enough at reparsing (because it's incrementally reparsing), but in some edge cases it can still take a few dozen or even hundreds of milliseconds (especially with big files).
Document completion (completion based on words in the current document) and search now also run on a background thread.
Text rendering
I completely reimplemented the high level part of text rendering (so basically text layout, styling and how draw commands for text and things like selections are generated) to support more advanced features, fix bugs, and improve performance.
- Nev should now be able to render very long lines and very large file (I tested up to 1GB. Load times aren't great, but then it runs well)
- I added support for custom inlay hints (technically even more general, you can replace an arbitrary range of text with arbitrary virtual text) This feature is used for several other features:
- Showing colored inlay hints next to colors like #AA77BB
- LSP Inlay hints
- Cursor jump mode
- Showing a custom prompt in custom command lines
- Much better line wrapping
- I fixed the scroll behavior for wrapped lines and the diff view, so now scrolling should always be a consistent speed.
- Smooth scrolling and horizontal scrolling
Text rendering implementation
Nev has a bunch of features like inlay hints, line wrapping, virtual text, aligning two files in a diff, expanding tabs, and in the future code folding. Supporting all of these with the old implementation was pretty hard and not very fast.
The new implementation works by taking the original document, and applying multiple transformations to it to transform it into what you will ultimately see on screen.
Currently the order of these transformations is this:
- Overlays: General transformation of text, so basically "replace range x with text y". This is used for e.g. inlay hints.
- Tabs: Expand tabs to whatever width is configured
- Line wrapping: If enabled insert newlines at certain points to break long lines
- Diff matching: Insert empty lines to align corresponding lines from two documents being show in a side by side diff.
Let's take a closer look at how the line wrapping transformation is represented. Take this sentence for example:
This is an example sentence which is quite long, I guess.
If the text is wrapped at let's say column 42, then what you would actually see on screen is this:
- This is an example sentence which is quite
- long, I guess.
This transformations is conceptually represented as an array of ranges:
[0:42 -> 0:42, 0:0 -> 1:0, 0:15 -> 0:15]
- 0:42 means 0 lines, 42 characters
- x -> y means x lines and characters are mapped to y lines and characters
So it basically means the first 0 lines and 42 characters from the unwrapped text are mapped to the first 0 lines and 42 characters in the wrapped version, or in other words they are unchanged. Next an empty range (0:0) is mapped to 1:0 (one line, zero characters), which basically means insert a newline. And at the end we have an identity mapping again.
This list of mappings is used to convert cursor locations between the wrapped and unwrapped version and for rendering.
To convert cursor locations using an array of ranges you could linearly search for the right entry by summing up entries until you reach the one you want, but this would be O(n), so not ideal.
You could also use binary search if you store the mapping in absolute coordinates instead of relative (so basically doing the summing once instead of on the fly). But then editing the array of mappings would be O(n) because you have to recalculate all ranges after the edit.
So instead these ranges are stored in sum trees, which allows O(log(n)) lookups and O(log(n)) edits of the ranges. They do however use a bit more memory.
The transforms for overlays and diff alignment are stored in a similar way, except the diff transform only stores lines ranges without column information and the overlay transforms store some extra data to support arbitrary replacement and grouping transforms by id.
To actually render the text there is a stack of iterators that returns chunks of text, which the renderer then simply displays. The actual rendering code has pretty much no knowledge of the individual features, it just receives chunks of text without line breaks and puts them on screen.
All the heavy lifting is done by the iterators, which almost exactly match the four transformations from above. There is one extra iterator for handling syntax highlighting which doesn't have a transform (because it only changes text styles, not content).
So the iterators are the following:
- Rope iterator: The rope already stores text in chunks. This iterator just returns those chunks, but split's them at new lines to simplify the following iterators. So all other iterators only deal with chunks that span one line.
- Syntax iterator: Applies syntax highlighting to incoming chunks, splits incoming chunks at syntax highlighting boundaries, and returns chunks with style information attached (e.g color)
- Overlay iterator: Takes in syntax highlighted chunks and uses it's sum tree of mappings to split/delete chunks coming from the syntax iterator or synthesize it's own chunks.
- Tab iterator: Takes in chunks, finds tabs and returns new chunks with tabs expanded.
- Wrap iterator: Takes in chunks, splits incoming chunks at wrap boundaries as specified by the sum tree of mappings.
- Diff iterator: Takes in chunks, inserts empty line chunks between some input chunks to align it according to it's mapping
Sum trees
Sum trees conceptually represent a list of values, the tree aspect is used to optimize certain operations on the tree like insertion/deletion/search/coordinate conversion (e.g. byte offset to line/column).
Nodes store multiple children, and only leaf nodes store values. For this example nodes will have up to three children.
All nodes store summaries of their children. These summaries are user defined, and for ropes it looks something like this:
type TextSummary* = object
bytes*: int ## How many bytes in the chunk/subtree
len*: Count ## Length in unicode code points
lines*: Point ## Point is a line/column pair, used to keep track of the number of newlines and number of bytes on the last lineThis data is stored on every node and keeps track of all information needed to convert from e.g. byte offsets to unicode code points, and so on.
Below is an example of a sum tree for the text "Hello world.\nHow are you??". The pairs of numbers represent the number of characters and number of new lines.
26,1
--------------------------------------------------------------------- Internal nodes. In this case also the root.
9,0 9,1 8,0
| | |
------------------------- ----------------------- ----------------------- Leaf nodes, store chunks of text
3,0 3,0 3,0 3,0 3,1 3,0 3,0 3,0 2,0
| | | | | | | | |
"Hel" "lo " "wor" "ld." "\nHo" "w a" "re " "you" "??"When modifying the text, the original tree is unchanged, and instead you create new modified nodes from a leaf to the root, and share unchanged subtrees with the old tree. This together with atomic reference counting means a specific instance of a sum tree can be shared with another thread, while the main thread "modifies" it at the same time, without having to worry about race conditions.
Currently ropes store Chunks of up to 128 bytes of text in the sum tree, and the sum tree nodes have up to 12 children. This means a leaf node will be the size of twelve chunks of 128 bytes, so 1536 bytes, plus a little bit for the summaries.
A 3000 line Nim file which is around 111 kB will produce a rope of height 2, with 71 leaf nodes, 7 internal nodes, and in total consume 172 kB bytes of memory, which means roughly a 50% overhead.
There is at least one optimization I plan on doing to reduce that overhead, hopefully to around 20-30%, but we'll see how effective that is.
Reworked settings
I improved a bunch of things about how config files/settings work, which means now:
- Config files are auto reloaded when you change them (can be disabled)
- Most settings are declared in the source code, which means I get compile errors when I misspell a setting name.
- There is an auto generated list of all settings and their documentation
- You can now specify settings in config files in a shortened form: { "ui.scroll-speed": 10 }
More details are in the docs
Removed NimScript
I decided to remove NimScript as a plugin mechanism. I constantly ran into issues where it kept breaking, including the Nim compiler increased my compile times a lot and load times for NimScript plugins were quite high.
So currently the only supported plugin mechanism is compiling Nim to WASM. I plan on redoing the plugin API some time this year as well, maybe use WIT to define it and generate the glue code, and switch to using Wasmtime to run plugins instead of Wasm3.
I do want some way of creating plugins without long compile times (compiling the vim motions which are implemented as a plugin currently takes more than 15 seconds), and I'm considering something like Lua, but I'm also considering using the AST language stuff for this. I already had a working prototype compiling an AST based language to WASM and calling the editor API, so it's definitely possible. Compile times so far were really fast as well (in the millisecond range, although the files were quite small), but because the whole thing is designed to do fine grained incremental compilation I expect the compile times to scale pretty well.
There are however still a few hard problems to solve with the AST language stuff (compiling needs to move to a background thread, rendering code is too complicated and buggy, editing code needs to be easy and fast), so I don't expect this to be a reality any time soon.
WASM treesitter parsers
Nev now supports WASM treesitter parsers, and if you have Nim and Emscripten installed you can install treesitter parsers with one command.
WASM parsers have the advantage that they are platform independent, can be loaded on Linux in the statically linked version of Nev (which can't load dynamic libraries because it uses Musl), and they are sandboxed.
Dynamic libraries are still supported.
At some point I might provide pre built WASM parsers somehow so that you don't need Nim and Emscripten to install parsers.
Color preview
Nev can show a preview of colors in your files as an inlay hint in front of the color definition. This can work for colors like #AABBCC or rgb(0.5, 0.5, 1) by specifying a regex to find and extract RGB values.
This feature is quite useful for creating themes (as well as themes now being auto reloaded).

Horizontal scrolling and line wrapping
So far line wrapping was always enabled because I didn't implement horizontal scrolling yet, but that is now possible, and so line wrapping can now be disabled.
Git integration
I added a bunch of improvements to the git view, which can now stage/unstage/revert individual changes in a file. I'm not happy with how this is implemented yet, but it works ^^.
You can now also jump between changes without having to switch focus to the preview.
Expression evaluation
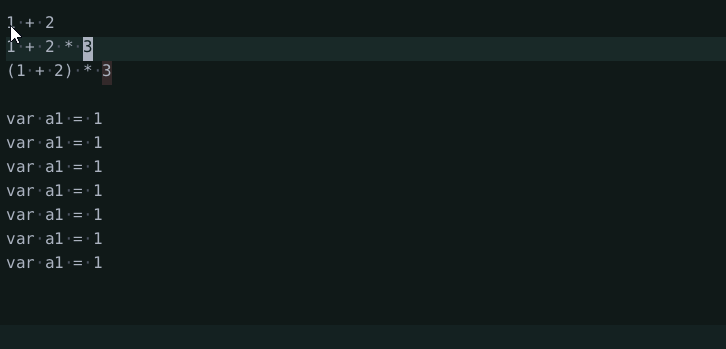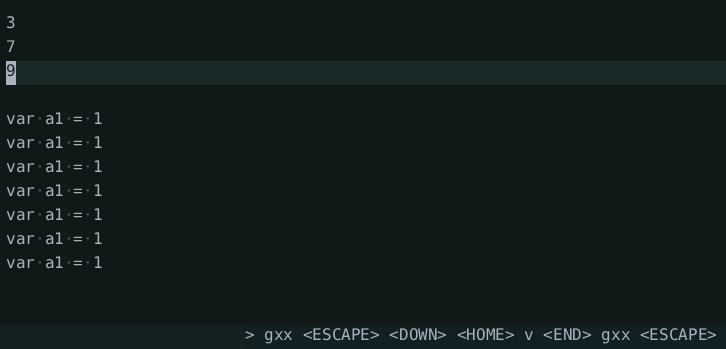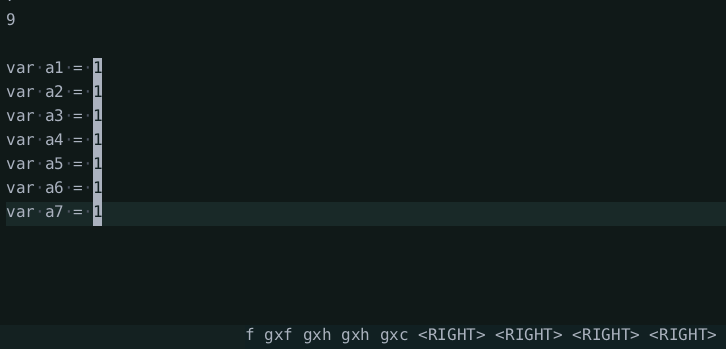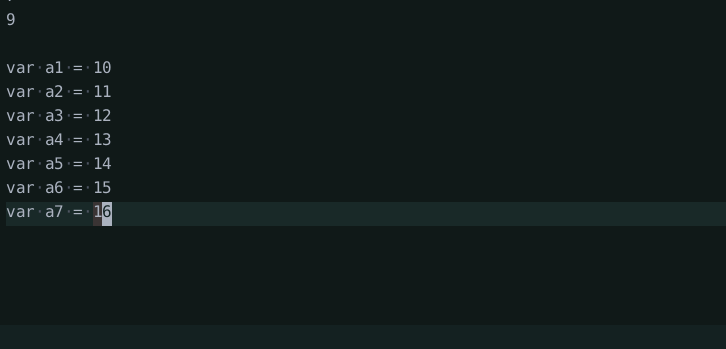
I added commands to increment/decrement numbers under the cursor and evaluate selected expressions (of number literals only). The evaluation is super basic and only supports binary and unary operators and number literals. It uses the builtin JavaScript treesitter parser to parse the text and a basic tree walk interpreter to evaluate it.
New pickers
I added a settings browser which allows you to see all settings from all config files and settings set at runtime, as well as change any setting. This is useful for temporarily trying out different settings or seeing where a setting is coming from.
There's also a keybinding explorer which shows all currently bound keybindings.
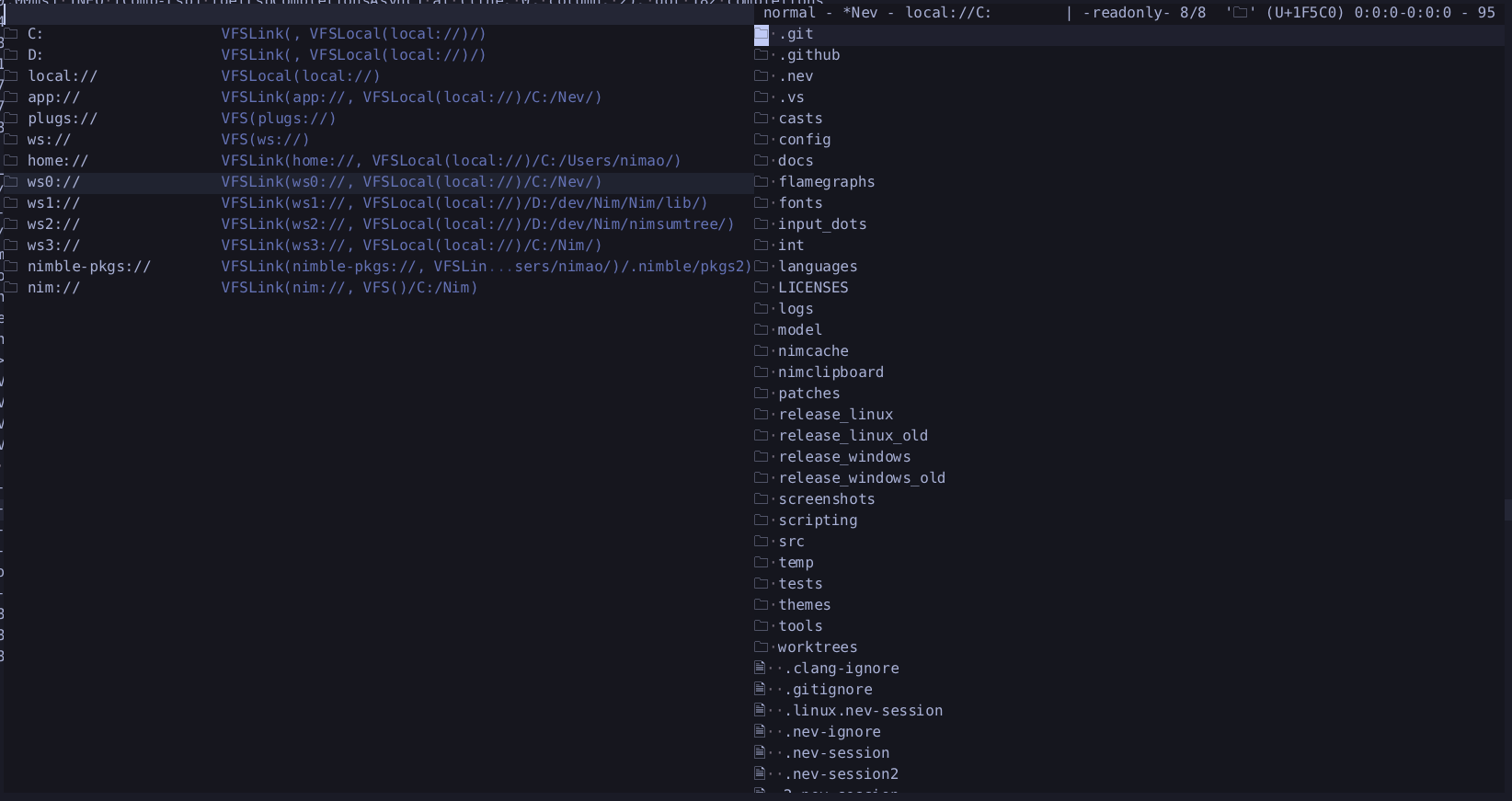
Virtual files system
I added a virtual filesystem abstraction where your local filesystem is mounted under local://, and workspace directories are mounted under ws0://, ws1:// etc. and act as links into some folder in the local filesystem (usually).
This turned out to be quite useful, and now a bunch of directories which are relevant for the editor or you are mounted in the VFS, like app:// which refers to the directory where Nev is installed and home:// which is your users home directory.
You can also mount additional directories using the mount-vfs command. I currently use this to mount the nimble package directory under nimble://, so I can quickly navigate to those packages.
I plan on adding support for remote filesystem eventually, not sure what exactly to support yet.
You can read more about the VFS here
There is also a VFS explorer which allows you to navigate the entire VFS, and add directories to your workspace by pressing C-a.
Regex based LSP features
Unfortunately so far nimlangserver wasn't able to handle the Nev codebase very well (probably too big). I haven't tried the latest version so maybe it improved.
So to get at least some of the LSP features I decided to add things like go to definition based on regexes.
It works by specifying a bunch of regexes for a language, which are then used by the editor to search in your workspace (using ripgrep). This has been surprisingly useful. It's very fast and reliable, but obviously not 100% accurate as it sometimes finds more results and (depending on how you define the regexes) sometimes less.
The regex based LSP features are used when no LSP is configured for the language and the required regexes are configured. And you need to have ripgrep installed.
Here is an example configuration for Nim:
"lang.nim.text.search-regexes": {
"goto-definition": "((proc|method|func|template|macro|iterator|type|^var|^let) [[0]]\\b)|(\\b[[0]]\\b.*?= (object|ref|ptr|array|set|tuple|enum|distinct|proc))|((type | +)\\b[[0]]\\b\\*?( \\{.*?)?:.+[^,;]$)",
"symbols": "((proc|method|func|template|macro|iterator|type) (\\b([a-zA-Z0-9_]+\\b)|(`.+?`)))|((\\b([a-zA-Z0-9_]+)|(`.+?`)\\b).*?= (object|ref|ptr|array|set|tuple|enum|distinct|proc))",
"workspace-symbols-by-kind": {
"Class": "(\\b([a-zA-Z0-9_]+)|(`.+?`)\\b).*?= (object|ref|ptr|array|set|tuple|distinct)",
"Function": "((proc|func|template|macro|iterator|type) (\\b([a-zA-Z0-9_]+\\b)|(`.+?`)))|((\\b([a-zA-Z0-9_]+)|(`.+?`)\\b).*?= (proc))",
"Method": "((method) (\\b([a-zA-Z0-9_]+\\b)|(`.+?`)))",
"Enum": "(\\b([a-zA-Z0-9_]+)|(`.+?`)\\b).*?= (enum)"
}
}With this configuration you can search for symbols in the current file (using the symbols regex), in all Nim files in your workspace (using the workspace-symbols-by-kind regex) and use go to definition to quickly find functions, types, macros etc.
The Nim regexes will for example not find any local variables (as there would be a lot of them), but it works for global variables/types/functions etc.
Sessions
I added a bunch of improvements to sessions:
- Nev now keeps track of recently opened sessions in ~/.nev/sessions.json
- You can open the last session you opened using nev --restore-session or nev -e
- You can open a session from your history using the open-recent-session command.
- You can open a session using the open-session command. This command takes a root directory and will search for .nev-session files in that directory and subdirectories and allow you to pick from the found sessions.
When you open a session using open-recent-session or open-session, Nev will open in a new window for now. I might add the ability to reuse the existing window later, but for that a bunch of resources need to be cleaned up when switching sessions.
If you use tmux or ZelliJ then Nev will open new sessions in a new pane instead.
You can read more here
Running shell commands
I added a basic way to run shell commands using the command run-shell-command. This command will basically reopen the Nev command line, but with a special handler that runs the entered command using a shell instead.
The intended way to use this is by binding this command to a key (bound to ! in the Vim keymap by default):
// keybindings.json
"editor": {
"!": {
"command": "run-shell-command",
"args": [{"shell": "powershell"}]
}
},This means when you press ! then it will open a special command line which will run the entered command using the shell specified in the setting editor.shells.powershell.
On Windows the default shell is powershell, on Linux it's bash.
Mostly unchanged
I didn't get any work done on the debugger UI (actually I probably broke something in there, so don't expect it to work), and not much on the Vim motions. Pretty much all the Vim motions I use are already there so I don't have much need to implement more, so contributions here would be very welcome ^^.
I also didn't get any work done on the AST language stuff, it doesn't even compile right now.
Future plans
- Rewrite the plugin API and make it much more powerful (custom UI, more performant access to document content, permissions, and much more)
- Create a reusable tree view which can be used for e.g. a file tree, symbol hierarchy, debugger variables, customizable by plugins
- Builtin terminal
- Make the debugger UI actually usable
- Add support for more LSP features
- and more
If you need help or want to contribute I'm on the Nim discord (not active but lurking), or you can create an issue on GitHub.
If anyone got this far, thanks for reading ^^
Huge respect for the great work you're doing! Looking forward to using Nev as my daily driver (haven't tried the new version yet, so maybe I already can).
It's so inspiring to see ambitious projects emerge in the Nim community. Nev, Figuro, Ferus just to name a few recently mentioned ones. Thank you all for your efforts 🙏
I think a post like this definitely deserves a spot on the Nim blog as well getting some attention on Hacker News.
If there's anything preventing you from using it as a daily driver let me know.
Also I just tried the deepwiki thing on Nev, it got a few things wrong/misleading but it's pretty impressive
ctrl+y completes the selected completion, ctrl+p and ctrl+n to select different completions
Thanks! I think ctrl+y isn't obvious. Or at least it's unusual after Vim or Helix.
are you using vim motions?
Yes. I've been using Helix lately, so I've actually switched to Helix motions but they're close enough.
@nimaoth got a couple of questions wrt configuration:
1. How do I map jj to set normal mode? Here's my // ~/.nev/keybindings.json file:
{
"editor.text.insert": {
"jj": "set-mode \"normal\"",
}
}What am I doing wrong?
- Is there a away to add aliases to commands? Like, q for quite, wq for write-file and quit, etc.?
You can't remap that in insert mode they way you want right now, I'll add that to my todo list. You have to use a key which doesn't produce a character like escape or ctrl+something.
Aliases don't exist yet but that sounds like a good idea. Until that exists you could create a plugin and add a custom command in there that does what you want:
import plugin_runtime
proc customQuit() {.expose("q").} =
## Close the editor
plugin_runtime.quit()
proc writeAndQuit() {.expose("wq").} =
## Save the current file and close the editor
plugin_runtime.writeFile()
plugin_runtime.quit()
include plugin_runtime_implActually I just realized that you can kind of already do that with tab if you add this to your keybindings.json:
"editor.text.completion": {
"<TAB>": "apply-selected-completion",
}This will cause tab to auto complete while the completion window is shown
- You can now define an alias for commands, with the ability to run multiple commands in one alias and forward arguments or supply default arguments (docs)
- You can now define multi key keybindings with keys which produce characters (like w) in modes that consume input (like insert mode) while still being able to insert the original key by waiting or pressing another key which is not in the bound sequence.
- Example: when you bind jj in insert mode to exit to normal mode, three things can happen:
- You press j once then after a configured delay the j will be inserted as text
- You press j twice in a row, faster than the configured delay, then it will exit to normal mode
- You press j once followed by another key (e.g k) faster than the configured delay. j will be inserted and the next key press will be handled as usual.
- Example: when you bind jj in insert mode to exit to normal mode, three things can happen:
- Added the ability to show signs on each line in a sign column, to show breakpoints, errors, code actions, etc.
If you're using prebuilt binaries you can download a build here, or just update to the latest commit on main.