Howdy, Nim peeps! I'm a Nim newb, straight out of C (and C++) land. Loving the language syntax, starting to love the flexible memory-management, but am having difficulty getting anything like C++ speed in runtime-resizeable arrays (the equivalent of C++ std::vector).
Please see the below test code. In this code, as run on a couple of test machines, Nim fixed-size arrays are just as fast as C arrays, but nim sequences are far slower than C++ vectors (which are, modulo some details, just as fast as C arrays). To my surprise, even Nim import of C++ vectors, via the 3rd-party cppstl library, is far slower than in native C++ ... at least, in this code, which I'm very much hoping is at fault in some way!
At least three possible reasons spring to mind:
- The code fails to make sure that the compiler does not optimize away loops. I've checked Godbolt assembly, and sum every element after the test ... I'd be surprised if that's the problem.
- The code is not generating SIMD instructions as fully as does the equivalent C++ code (for default alignments and no extra pragmas). My assembly-fu (via Godbolt) is weak enough that I can't be quite sure of this.
- The code is falling victim to pointer indirection slow-down when testing both sequences and imported C++ vectors. I am hoping to learn that this is due to newb mistakes.
Right now, I have two concerns:
- Does Nim code convince the underlying compiler to generate SIMD instructions in cases where programmers might reasonably expect it to? (i.e., in cases where native C or C++ code does)
- Does pointer indirection cost the same in Nim as it does in either C or C++, or is this cost much greater?
Editorial note: Every potential replacement for C/C++ I've tried, Rust excepted, has fallen down disturbingly quickly on at least one of these two metrics. I really want Nim to win with me here, because - if it can - I think I can win with Nim.
# import cppstl # For C++ vectors
# import math # For sqrt, etc.
import std/monotimes
import std/times
import std/strformat
type
type_t = uint8 # if you change this to float, adjust the div operators (or import lenientops)
# We test arrays of a given size on disk. We therefore adjust for the size of elements in bytes.
const array_elements = 1 * 1024 div sizeof(type_t)
# Test the speed of various Nim array options.
# We first want to confirm that Nim arrays are just as fast as they are in C/C++. They are.
# We then want to confirm that Nim runtime resizeable arrays are just as fast as C++ vectors.
# We haven't succeeded here. Even C++ vectors are far slower through Nim then they are in native
# C++ code, as least as this codebase uses them.
var test_array: array[array_elements, type_t] # stack-allocated array - very fast
# var test_array_ptr = create(array[array_elements, type_t]) # Heap-allocated array - very fast
# var test_array = test_array_ptr[]
# var test_array = newSeq[type_t](array_elements) # heap-allocated sequence - very slow
# var test_array_ptr = test_array[0].unsafeAddr # Not sure how to use this efficiently
# C++ vectors - surprisingly slow in this Nim codebase
# var test_array = initCppVector[type_t](array_elements)
# echo "vector size/capacity: ", test_array.size, "/", test_array.capacity,
# " (currently stored elements)/(maximum storage without resizing)"
# Fill with 0 to (maxval for this data type), repeating
for i in 0 ..< array_elements:
test_array[i] = type_t(i) # Wrap-around is expected behavior here
# test_array_ptr += sizeof(type_t)
# test_array_ptr[] = type_t(i);
var cycles:int64 = 1_000_000_000'i64 div array_elements div sizeof(type_t)
if cycles < 32: cycles = 32 # Insure enough looping for a valid test
var start_time = getMonoTime()
for c in 0 ..< cycles:
for i in 0 ..< array_elements:
# Wrap-around is expected behavior here
test_array[i] += 3 # fast with arrays, slow with sequences
# test_array[j].unsafeAddr[] += 3 # just as slow as using seq[j] directly
var end_time = getMonoTime()
var ns_per_element:float = float(inNanoseconds(end_time - start_time)) / float(cycles) / float(array_elements)
echo "addition by 3, ns/element: ",
fmt"{ns_per_element:.3f}" # skip the array check; we test more throughly below
# Check that all calculations are performed, and that the sum is consistant.
# For an uint8 array with 1024 elements, the sum should be 130_560.
var sum: int = 0
for i in 0 ..< array_elements:
sum += int(test_array[i]) # Will wrap-around for large arrays with wide datatypes
echo "Sum is: ", sum
When you use array, doesn't compiler calculate sum at compile time and remove the loop? If result of your program can be calculated at compile time as the compile knows all inputs, compiler generates a code that just print text without executing other code at runtime. Using some runtime values (read stdin, program parameters, files, etc) prevents such a optimization. Does your C/C++ code really run the code inside the loop? Did you read assembly code on godbolt?
--passC:-march=native option allows using any instructions on the CPU on the build machine. So it might generate SIMD instructions. But generated code might not run on other CPUs.
- (re)checked the assembly in Godbolt. Still unsure of SIMDing, but can point to the exact instruction that adds exactly three inside the loop. The sum is also not optimized away.
- To make doubly sure (as this is compiler-specific), I added the following code right after array initialization and before the initial time check. It turns the value to add into a run-time variable. No effect on speed in Nim static arrays, for sufficiently long test times.
# Save a user-specified value to add to each element in the array
stdout.write("Add how much to each element in the array, per cycle (must be an integer): ")
#
var to_add:type_t
try:
let tmp = readLine(stdin)
to_add = type_t(parseInt(tmp))
except:
echo "Could not read number!"
(and, below, replace the addition of 3 with "to_add" in the loop)
I think sequences are designed for general purpose, not for ultimate speed. And due to the additional complexity (that the size can change), it cannot be as fast as arrays. For example, it has boundary checks. To perform such a check, the program has to first load its current length and then compare it with the index. Arrays also have this check, but their lengths can't change. Try compiling with --boundChecks:off. Also try --opt:speed --mm:orc. Sometimes these options also matter.
As for std::vector, try using the C++ iterator (the internal pointer) instead of indices.
Also .unsafeAddr[] is a no-op. It's just *& and will likely be optimized out, or decrease the speed if not.
- backend compilers fail to understand how Nim generated seq related code can be optimized up to C++ vector level.
- backend compiler have a special "bless" for C++ vectors that Nim should mimick.
- Nim seq implementation is not as optimized as possible for compatibility reasons.
- An alternative Nim seq as performant as C++ vector exists right now.
With your test, using either seq or the wrapped C++ std::vector does indeed prevent vectorization. Using a MinGW GCC compiler on Windows and compiling with -d:release, the annotated x86_64 assembler output for the data[i] += 3 loop (when data is a seq[type_t]) looks like this:
.L11:
# i_4 = ((NI)0);
xor ecx, ecx # i_4
.L7:
# if (i_3 < 0 || i_3 >= test_array__test_u4
cmp rdx, rcx # _10, i_4
jle .L41 #,
# test_array__test_u46.p->data[i_3] += ((NI
mov r9, QWORD PTR test_array__test_u46[rip+8] # _13, test_array__test_u46.p
# test_array__test_u46.p->data[i_3] += ((NI
add BYTE PTR 8[r9+rcx], 3 # _13->data[i_4_174],
# if (nimAddInt(i_4, ((NI)1), &TM__jlW9bPLg
add rcx, 1 # i_4,
# if (!(i_4 < ((NI)1024))) goto LA14;
cmp rcx, 1024 # i_4,
jne .L7 #,
No SSE instructions are used and the elements are updated one by one.
There are two reasons for why no vectorization takes place.
The first one is that in Nim, all var and let locations defined at the module level (i.e., outside of any procedures) are globals, and thus put into the executable's data section rather than on the stack. In other words, in its current form, your test is (apart from the logging) equivalent to the following C++ code:
#include <cstdint>
#include <vector>
#include <iostream>
#include <chrono>
std::vector<std::uint8_t> test_array; // note the global variable
int main() {
const int array_elements = 1024;
test_array.resize(array_elements);
for (int i = 0; i < test_array.size(); i++) {
test_array[i] = i;
}
std::uint64_t cycles = 1000000000 / array_elements;
if (cycles < 32) cycles = 32;
const auto start_time = std::chrono::high_resolution_clock::now();
for (int j = 0; j < cycles; ++j) {
for (int i = 0; i < array_elements; i++) {
test_array[i] += 3;
}
}
const auto end_time = std::chrono::high_resolution_clock::now();
const auto ns_per_element = float(std::chrono::duration_cast<std::chrono::nanoseconds>(end_time - start_time).count()) / float(cycles) / float(array_elements);
std::cout << "addition by 3, ns/element: " << ns_per_element << "\n";
int sum = 0;
for (const auto it : test_array) {
sum += int(it);
}
std::cout << "Sum is " << sum << "\n";
return 0;
}
For me, the MinGW GCC also fails to vectorize the loop here when compiling with gcc -O3.
Wrapping the Nim test in a procedure, like so:
proc main() =
var data = newSeq[type_t](array_elements)
# ...
for c in 0..<cycles:
for i in 0..<array_elements:
data[i] += 3
# ...
The second problem are the bound checks that are inserted on every seq access (which is, by default, not the case for C++'s 'std::vector). In the assembler output from earlier, this is the cmp rdx, rcx; jle .L41 instruction pair. However, bound checks can be disabled:
- for the whole program via the command line option --boundChecks:off
- for a procedure by wrapping it in {.push boundChecks: off.}/{.pop.}
Wrapping the test in a procedure and disabling bound checks enables GCC to vectorize the loop(s):
movdqa xmm1, XMMWORD PTR .LC10[rip] # tmp283,
mov edx, 1 # ivtmp.80,
.L3:
# if (!(i_4 < ((NI)1024))) goto LA14;
mov rax, rdi # ivtmp.68, ivtmp.47
.L6:
# test_array.p->data[i_3] += ((NI)3);
movdqu xmm0, XMMWORD PTR [rax] # vect__27.34, MEM <vector(16) unsigned char> [(unsigned char *)_8
add rax, 16 # ivtmp.68,
paddb xmm0, xmm1 # vect__27.34, tmp283
movups XMMWORD PTR -16[rax], xmm0 # MEM <vector(16) unsigned char> [(unsigned char *)_89], vect__
cmp rax, rbx # ivtmp.68, _223
jne .L6 #,
add rdx, 2 # ivtmp.80,
cmp rdx, 976561 # ivtmp.80,
jne .L3 #,
# test_array.p->data[i_3] += ((NI)3);
mov rcx, rdi # ivtmp.64, ivtmp.47
.L11:
movzx eax, BYTE PTR [rcx] # test_array$p__data_I_lsm0.44, MEM[(unsigned char *)_120]
mov edx, 2 # ivtmp_21,
jmp .L9 #
.L24:
# if (!(i_4 < ((NI)1024))) goto LA14;
mov edx, 1 # ivtmp_21,
.L9:
# test_array.p->data[i_3] += ((NI)3);
add eax, 3 # test_array$p__data_I_lsm0.44,
# if (!(i_4 < ((NI)1024))) goto LA14;
cmp rdx, 1 # ivtmp_21,
jne .L24 #,
mov BYTE PTR [rcx], al # MEM[(unsigned char *)_120], test_array$p__data_I_lsm0.44
# if (!(res < cycles)) goto LA11;
add rcx, 1 # ivtmp.64,
cmp rcx, rbx # ivtmp.64, _223
jne .L11 #,
Does pointer indirection cost the same in Nim as it does in either C or C++, or is this cost much greater?
Pointer indirection in Nim has no run-time overhead compared to the C or C++ counterpart. There's the nilChecks pragma option seemingly reserved for future use, but it does nothing at the moment.
Zerbina,
Outstanding post! Fully answers all of my concerns. Thank you very much for it.
Nim is clearly a learning experience for any newbie ... and what the "pain points" are will very much depend on one's coding background.
In my case, being from a C/C++ background, I have to keep in mind that Nim compiles to C or C++, and an external compiler takes things down to machine code.
Araq,
While the resource you've pointed us to is absolutely invaluable for the serious and experienced Nim programmer - and, so, thank you very much for it ...
... it is not merely the case that I am neither of these things, but:
For the newbie, that's the sort of thing that will either "just work" or "just not work".
Happily, there seems to be good news on that front in this case! :-)
(editoral note: RST auto-styling is just not my favorite.)
While this has been a problem in the past with latest clang version 16.0.6 on linux and a simple example:
const
Size = 10000006
proc dot(a, b: seq[float]): seq[float] =
result = newSeq[float](Size)
for j in 0 ..< 200: # some repetitions
for i in 0 ..< Size:
result[i] = a[i] * b[i]
proc main =
var a = newSeq[float](Size)
var b = newSeq[float](Size)
var c = a.dot(b)
main()
It seems that it is correctly autovectorized:
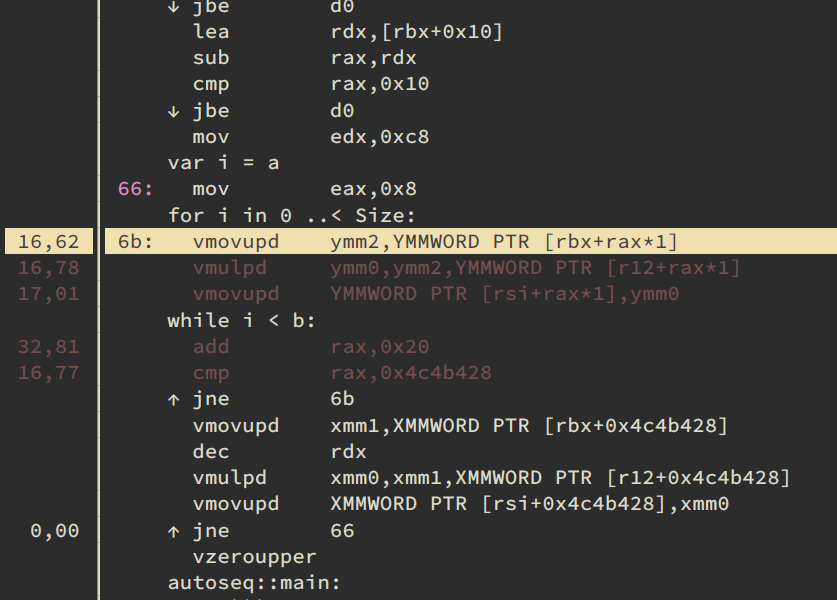
It seems that it is correctly autovectorized
Awesome news! :-)